




Table Of Contents
Developers Must Know Database Design
Developers who do any kind of backend work are inevitably going to wind up modifying or adding to the database schema(s) of an application. Developers at start ups even more so are going to be wearing many hats including database architect. If this is you - you must learn database design.
Database design is a massive topic and like many things in software it’s growing all the time. But there are two key concepts that will massively improve the way you design your schemas.
- Entity Relationship Modeling
- Database Normalization
We’ll touch on these more in depth in the next sections of this article but let’s first talk about what happens if you neglect database design.
Neglecting your schema
Failing to implement good database design in a schema is one of the biggest mistakes developers can make.
One of two things will happen.
Snowball technical debt
There is no avoiding coupling between application logic and your database schema. Your application can’t automatically predict what data point you are trying to retrieve from your database- you have to tell it. And often times you have to tell it in many places.
When you poorly design your database schema you create a snowball of technical debt. Whether it be because your columns are being used for multiple purposes and contain unpredictable or complex data or because you have the same column duplicated across many tables and nobody knows why: poor schema design is not only going to slow down development, it’s going to make bugs nearly impossible to avoid.
And like with any technical debt in software this has a snowball effect. Anything built on this system will inherit the same issues and require post-hoc band-aid fixes, and stuff gets built on top of that with the same result, ultimately snowballing into massive technical debt.
Ticking time bomb refactor
Highly related to technical debt: the ticking time bomb refactor. A poorly designed schema in some cases will simply not be able to meet business needs as they become more complex.
This is particularly true of schemas that fail to partition tables and model out entity relationships properly. When your schema insists that two entities share a particular relationship (one-to-one, one-to-many, etc) but your business needs insist they share a different relationship, you have no choice but to redesign your schema.
Entity Relationship Modeling
“Entity–relationship modeling was developed for database and design by Peter Chen and published in a 1976 paper”

Entity Relationship Modeling is a particular modality for modeling out… entities and relationships between them. It’s somewhat self explanatory. And it translates very well to database design due to this innate intuitiveness.
Entities are represented as tables in your database. For example a “users” table and a “tasks” table in a basic to-do app.
Relationships are the associations between these tables. For example the one-to-many relationship between the “user” table and the “tasks” table in a basic to-do app.
Let’s go into more depth with these two concepts.
Entities
To get a little semantic we can define an entity as “That which has a distinct existence as an individual unit.”
Entities can be abstract concepts or numbers (think- emotions) or particular objects (think- people).
When it comes to designing a schema it’s important to map out what entities you care about storing and what properties they have. Your table names should be named after the entity they represent and the columns underneath them should represent some data point about the entity.
Here is an example of a poorly defined schema. Take a look at it and see if you can spot the issue.
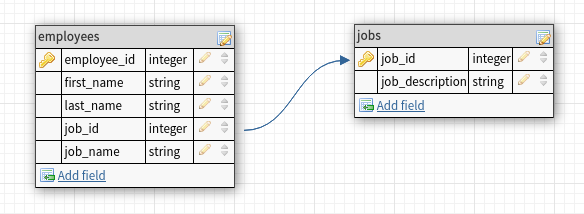
In the image we have a problem with how our entities are defined. The job_name field doesn’t belong under the employee entity. The name of a job is a property of a job, not an employee! This of course doesn’t apply to the job_id field because it’s a foreign key - these are an exception to the rule as they’re needed to create associations between tables.
And it’s really that simple folks. Aside from highly complex and nuanced cases (and if you’re working with schemas at that level you probably don’t need to read this article) if you are ever wondering where to put a column simply ask yourself: what entity is this a property of?
You would be amazed at how getting this part of your schema wrong can create so much confusion and cause so many issues with development in the future.
Relationships
Relationships are simply the associations between your entities. They can follow one of three patterns.
- One-to-one: One entity X is related to only one entity Y. An example could be the relationship between a coach and a soccer team. Each soccer team has exactly one coach and one coach belongs to exactly one soccer team.
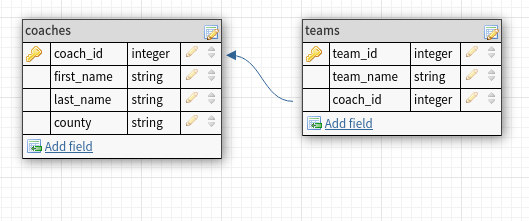
To enforce the one-to-one relationship between coaches and teams in this schema we would likely want to ensure the coach_id in the teams table has a unique key constraint.
- One-to-many: One entity X is related to many entities Y. Following the above example, if we could assign one coach to multiple teams we would see a one-to-many relationship.
Interestingly, there are a few ways you can model this in your schema. We could in fact reuse the schema above and simply remove the unique restraint on coach_id in the teams table. This way we could have multiple teams reference the same coach. This is probably the best approach because it’s the most simple.
Another way would be using an intermediary relationship table called teams_coaches which will be described in the next section.
(Quick note- if using an intermediary relationship table for a one-to-many relationship, you’d need to ensure the team_id in the intermediary table is unique so a team is only ever associated with one coach. This would still allow a coach to be associated with multiple teams.)
- Many-to-many: Many entities X are related to many entities Y. This would be the case if multiple coaches could be assigned to multiple teams and teams could have multiple coaches.
The schema in this case might look something like this:
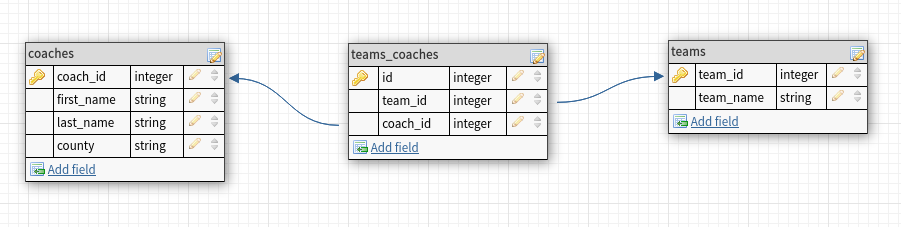
You can see we now have a table explicitly tracking the associations between coaches and teams called teams_coaches. This table allows us to define as many associations as we want for coaches and teams.
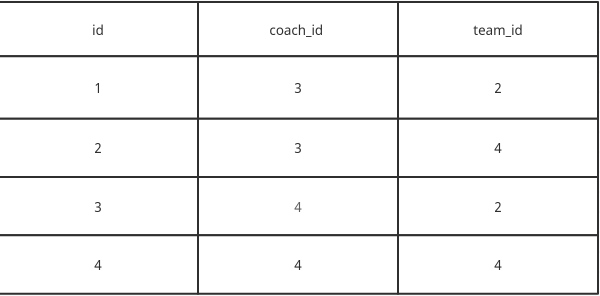
As you can see we have many coaches associated with many teams. Some are even associated with the same team!
ER modeling is about sane design
ER modeling is really just about logically organizing your data in a sane way. For most applications this isn’t that hard. If you can identify what type of associations you need, and what data comprises your entities / tables, you are on the right track to setting down a solid foundation for your database.
Database Normalization
Database normalization is a series of design techniques for your database schema that reduces redundancy, creates better cohesion between data points and entities, and overall ensures you have a logical structure in your schema.
There are 6 main “forms” or “levels” of normalization in a schema. Each form is defined with specific criteria. To design a coherent database schema you need to know exactly two of these forms.
First normal form (1NF)
- Each table cell should contain a single value.
- Each record should be unique.
Here is an example of a 1NF table.
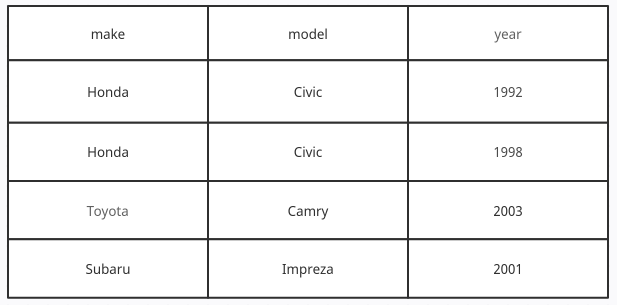
Notice how each cell contains exactly one value and how each record (row) is distinct in some way.
Having unique records gets rid of redundancy. Duplicate records only serve to eat up storage space. The benefit of having table cells contain a single value is that reading and processing that data later is much easier. When your cells contain more than one value they become less predictable and typically require some additional parsing to read.
I’m personally on a project right now where many table cells throughout the database do not follow 1NF and it is a pain in the ass to build ETL tasks to process them. It not only makes parsing and transforming the data difficult, it eats up a ton of performance because you often can’t do simple equality checks, you have to use some form of pattern matching which is very slow.
Second normal form (2NF)
- The table should be in 1NF.
- The table should have an independent single-column primary key.
To transform our 1NF table above into 2NF we simply need to add a primary key that is functionally independent from other columns in the table.

It’s really that simple. We’ve thrown in a column named “id”.
In most databases this would be an auto incrementing column solely for the purpose of uniquely identifying a record in a specific table. It doesn’t care about other values in the table. It’s just like a finger print for each record.
The primary value of using functionally independent primary keys like this is it makes foreign key constraints incredibly simple to implement.
If we need to associate customers with particular cars for example, we can implement the following schema:

Bonus question: Which ER association type do you think the above schema is using?
Conclusion
Much like building the foundation of a house if you create a mangled disaster of a database schema it is going to haunt every aspect of the software built on top of it until it’s fixed.
Do yourself, your team, and your company a favor- learn proper database design. Basic normalization strategies and sane entity-relationship modeling is a fantastic start and will help you avoid the vast majority of design errors with your database.
So next time you’re handed a task that requires you to modify your schema or create a brand new one: take your time, understand your ER model, and come back to this article if you need to.
Godspeed.
Tags
